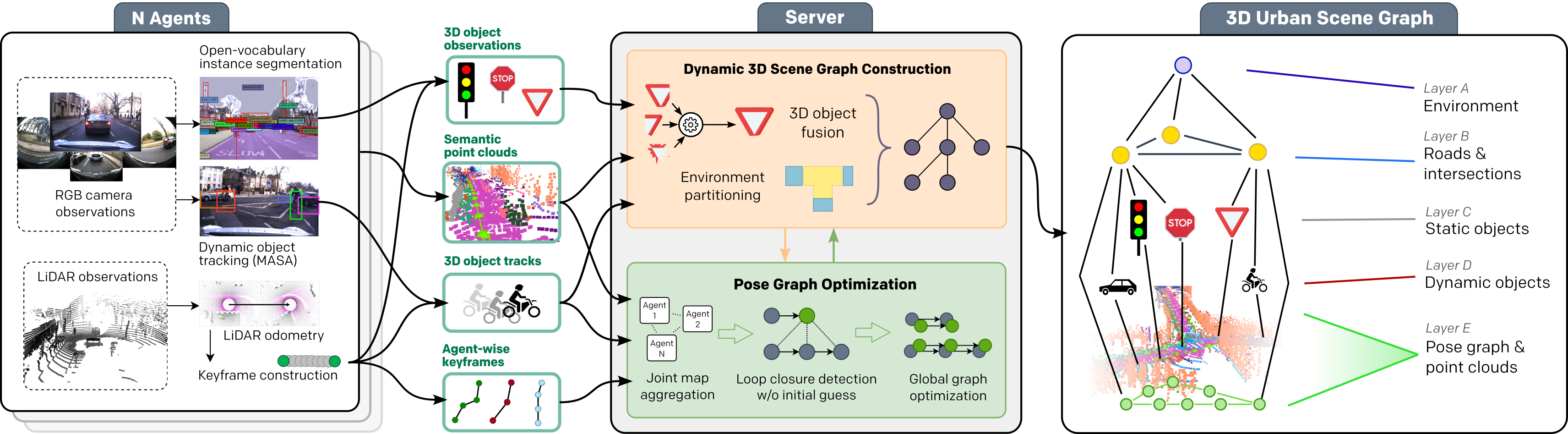
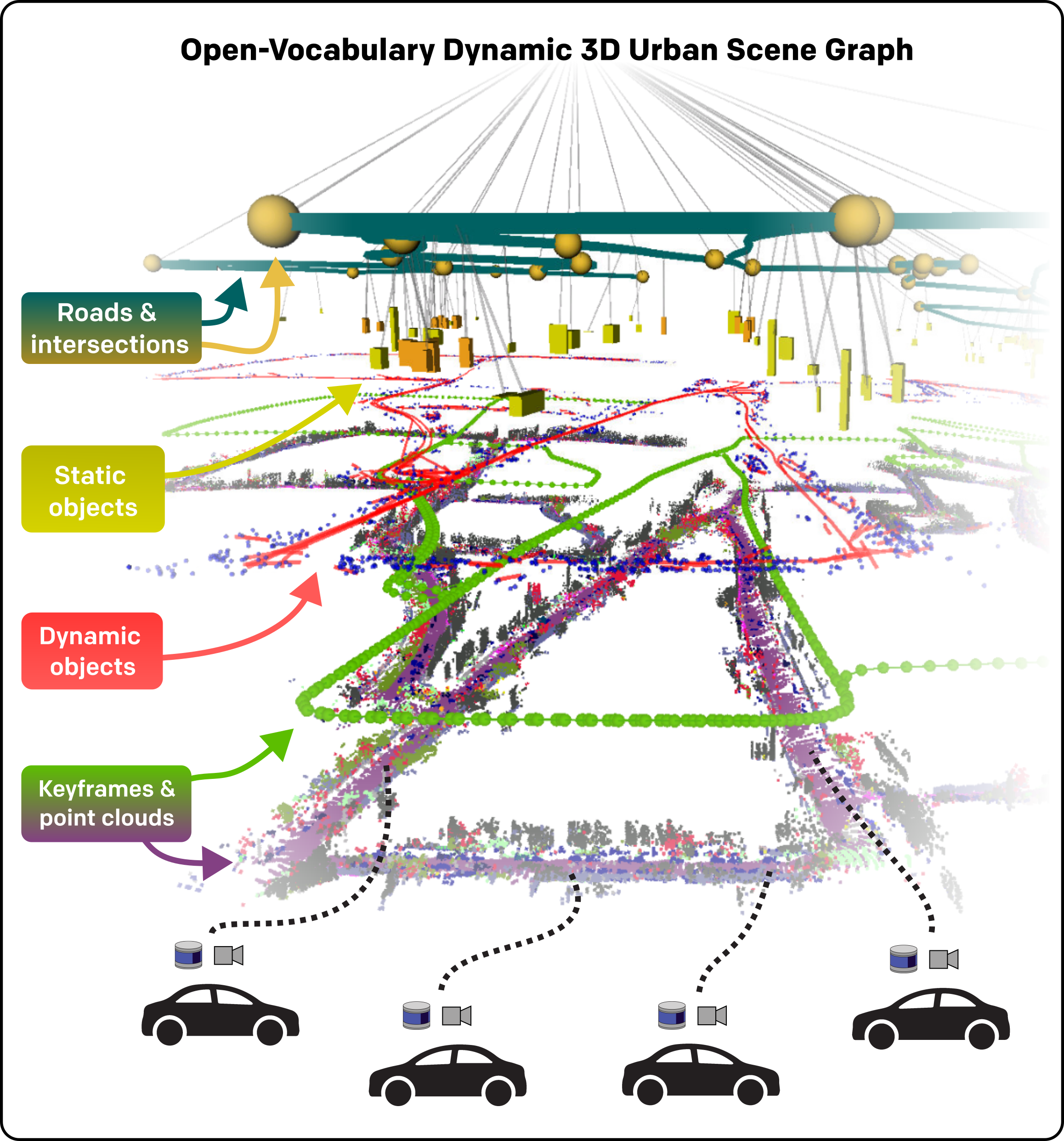
Mapping and scene representation are fundamental to reliable planning and navigation in mobile robots. While purely geometric maps using voxel grids allow for general navigation, obtaining up-to-date spatial and semantically rich representations that scale to dynamic large-scale environments remains challenging. In this work, we present CURB-OSG, an open-vocabulary dynamic 3D scene graph engine that generates hierarchical decompositions of urban driving scenes via multi-agent collaboration. By fusing the camera and LiDAR observations from multiple perceiving agents with unknown initial poses, our approach generates more accurate maps compared to a single agent while constructing a unified open-vocabulary semantic hierarchy of the scene. Unlike previous methods that rely on ground truth agent poses or are evaluated purely in simulation, CURB-OSG alleviates these constraints. We evaluate the capabilities of CURB-OSG on real-world multi-agent sensor data obtained from multiple sessions of the Oxford Radar RobotCar dataset. We demonstrate improved mapping and object prediction accuracy through multi-agent collaboration as well as evaluate the environment partitioning capabilities of the proposed approach.